c语言实现数据结构---关于实现各种排序算法-创新互联
正好刚写了线性表相关的实现,直接看排序
站在用户的角度思考问题,与客户深入沟通,找到盐田网站设计与盐田网站推广的解决方案,凭借多年的经验,让设计与互联网技术结合,创造个性化、用户体验好的作品,建站类型包括:成都做网站、网站制作、企业官网、英文网站、手机端网站、网站推广、域名注册、虚拟主机、企业邮箱。业务覆盖盐田地区。

目录
算法实现的准备:
稳定排序
冒泡排序
直接插入排序
归并排序
不稳定的排序
希尔排序
希尔排序效率问题
快速排序
选择排序--简单选择排序
选择排序--堆排序
算法实现的准备:我看参考教材上是用结构体实现的,我有点不理解,所以……我直接用了数组,算法嘛,思想会了就行。
#define MAXSIZE 1000//初始空间大小
int arry[MAXSIZE];
//sort
#define swap(a,b){\
__typeof(a) _temp = a ; a = b ; b = _temp;\
}一种最简单的交换排序方法,就是对于长度为n的待排序列,从前向后(或者从后向前),对相邻的两个元素进行两两比较,若是逆序,交换两个元素,依次类推,直到n-1,n这一组
举例:

void Bubble(int *a, int len){
bool f = true;
for(int i = 0; i< len && f; i++){
f = false;
for(int j = 0; j< len - i; j++){
if(a[j] >a[j+1]){
swap(a[j], a[j+1]);
f = true;//true表示有记录交换
}
}
}
for(int i = 0; i< len; i++){
cout<< a[i]<< " ";
}
cout<< endl;
return ;
}就是在数组的最前面建立一段有序区,然后从后面依次拿元素插入到前面的有序区。
基本思想:依次将一个待排序的元素按其元素大小插入到已经排序完成的有序表中,得到一个有序长度增1,无需部分减1的表(我用的顺序表,数组)
举个例子:

void Insert(int *a, int len){
//int k;
for(int i = 1; i< len; i++){
//int k = a[i];
if(a[i] >= a[i-1])
continue;
for(int j = i; j >0; j--){
if(a[j] >= a[j-1])
break;
if(a[j]< a[j-1])
swap(a[j], a[j-1]) ;//因为前面是有序的所以我想的是直接冒泡上去
}
}
for(int i = 0; i< len; i++){
cout<< a[i]<< " ";
}
cout<< endl;
return ;
}思想是将两个或者两个以上的有序表合并成一个有序表。
无论是链式存储还是顺序存储,都可在O(m+n)(两个有序表的长度分别为m和n)的时间量级上实现归并排序,归并排序有多路归并和2-路归并排序,可用于内部排序,也可用于外部排序。
void mergearray(int *a,int l,int mid,int r,int *temp)
{
//int *temp = (int*)malloc(sizeof(int) * (r-l+1));
int i = l, j = mid+1;
int m = mid, n = r;
int k=0;
while(i<= m && j<= n){
if(a[i]< a[j])
temp[k++] = a[i++];//把前一部分的一个元素放到temp中
else
temp[k++] = a[j++];
}
while(i<= m)
temp[k++]=a[i++];
while(j<= n)
temp[k++] = a[j++];
for(int i = 0; i< k; i++)
a[l+i] = temp[i];
}
void merge(int *a,int l,int r,int *temp)
{
if(l< r)
{
int mid=(r + l)>>1;
merge(a, l, mid, temp); //左边有序
merge(a, mid+1, r, temp); //右边有序
mergearray(a, r, mid, l, temp); //再将两个有序数组合并
}
}不稳定的排序 希尔排序有时候算法可能在写的过程中才能完全会
也叫缩小增量排序,是对直接插入排序的改进
希尔排序过程:
①取正整数d(d
②缩小增量d,例如取d=[a/2],重复上述过程,再对每个子序列分别进行直接插入排序。
③最后取d=1,将待排序序列放在一起进行一 次直接插入排序。
例如,待排序的初始关键字序列为28,35,12, 19,46, 54, 12,09,15,33,进行希尔排序的过程如图:

void ShellInsert(int a[], int dk, int len){
//对顺序表进行一趟希尔排序
for(int i = dk+1; i< len; i++){
if(a[i]< a[i-dk]) {
int t = a[i];
for(int j = i-dk; j>0 && t希尔排序效率问题(1) 时间效率
算法的效率取决于增量的取值,这是一个未解决的数学难题。 希尔增量般的取值是d=[n/2」, 并且最后一个增量- 定为1。排序中子序列的构成不是简单的“逐段分割”,而是将相隔某个增量的记录组成一个子序列。当增量采用Hibbard增量时,,希尔排序的时间复杂度为0(n的1.5次方)希尔排序时间复杂度的下界是O(nlog2n)。
(2) 空间效率
本算法只需要个辅助空间, 用来作为“哨兵”,所以空间复杂度 S(n)=O(1)。
(3)稳定性
在不同子序列的插入排序过程中,相同的元素可能在各自的插入序列中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的排序方法。
快速排序快速排序是基于分治法的一种排序方法,是对冒泡排序的一种改进,他是目前内部排序中排序速度较快的一种方法。
基本思想:通过一趟排序将待排序记录分割成独立的两部分,其中一部分的关键字均不大于另一部分的关键字,可分别对这两部分记录继续进行排序,以达到整个序列有序的目的
内部排序:排序记录放在计算机存储器里面进行的
进们快速排序的具体过程如下。
对R[s], . R[t]中的记录进行一趟快速排序, 附设两个指针low 和high,设置一个板轴记录R[0]=R[s],pivotkey=R[s] .key。
①令10ow=s, high=t,并保存low位置的记录。
②从high所指位置起向low所指位置方向搜索,找到第1个关键字不大于pivotkey的记录,放在low位置处,并使low++。
③从low所指位置起向high所指位置方向搜索,找到第1个关键字不小于pivotkey的记录,放在high位置处,并使high--。
④重复②、③两步,直至low=high为止(此时整个序列被分成有序的前后两块)。⑤将轴元素放在low位置处。
⑥再分别对两个子序列进行快速排序,直到每个子序列只含有一个记录为止。每一趟快速排序,都可将枢轴元素放在其最终的位置上。
例如,待排序的初始关键字序列为(28, 35,12, 19, 46, 54, 12, 39),进行快速排的过程如图:

教材上是线性表实现的,而且有点复杂,我就用到之前的方法写的代码,也是相同的思想
void quick_sort(int*num,int l,int r){
if(r<=l) return;
int x=l,y=r,z=num[l];
while(x=z)--y;
if(x>len;
for(int i = 0; i< len; i++){
cin >>arry[i];
}
//Insert(arry, len);
//Bubble(arry, len);
quick_sort(arry, 0, len-1);
for(int i = 0; i< len; i++){
cout<< arry[i]<< " ";
}
return 0;
}
选择排序--简单选择排序选择排序基本思想:每一趟从待排序的记录中选出关键字最小记录,按顺序放在已排好序的子序列的最后,直到全部记录排序完毕。
简单选择排序是选择排序中最简单的-种排序方法,其基本思想是:第i(1≤i
简单选择排序的具体过程如下。
①让i等于1。
②取R[i].key,依次与记录R[i+1]~R[n]的关键字进行比较,找出从第i条记录到第n条记录中关键字最小的记录L.R[j],交换L.R[i]与L.R[j],使第i个位置上的记录成为从第i个记录起到第n个记录为止的记录序列中关键字最小的记录。
③让i的值增加1,转向②,直到对R[n-1].key与R[n].key进行比较并进行相应的处理为止,最终得到一一个有序的序列。

void selet(int *a, int len){
for(int i = 0; i< len-1; i++){
int k = i;
for(int j=i+1; j< len; j++){
if(a[k] >a[j])
k = j;
}
swap(a[k], a[i]);
}
return;
}
int main()
{
int len;
cin >>len;
for(int i = 0; i< len; i++){
cin >>arry[i];
}
//Insert(arry, len);
//Bubble(arry, len);
//quick_sort(arry, 0, len-1);
selet(arry, len);
for(int i = 0; i< len; i++){
cout<< arry[i]<< " ";
}
return 0;
}
选择排序--堆排序 堆排序是对简单选择的改进,主要是为了减少排序过程中记录的比较次数。在堆排序中,将待排序列逻辑上看作是一颗完全二叉树,并用堆来选择待排序列的极值,从而达到最终的排序目的。
堆的定义:对于含有n个元素的序列,若其对应的关键字序列,满足下列关系:
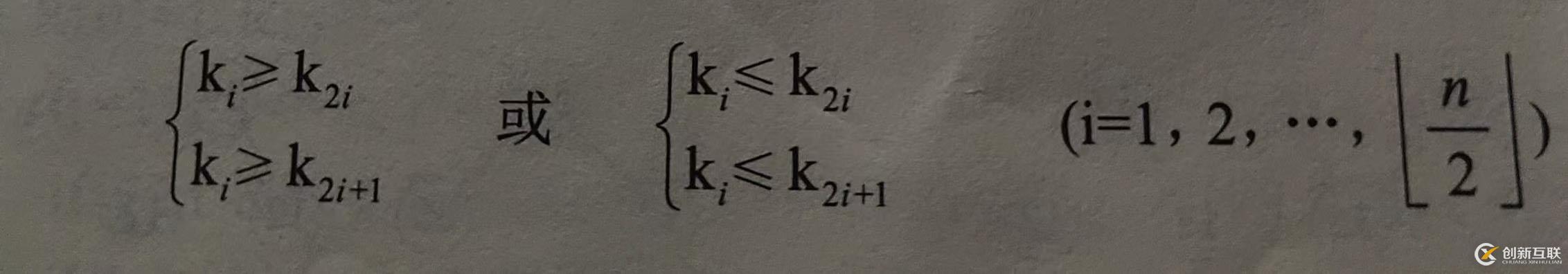
若将顺序存储的待排序中的关键字序列看作是一棵完全二叉树,则堆的含义表明:完全二叉树中所有非终端结点的值均不小于(或者不大于)其左、右孩子结点的值,相应的这样的完全二叉树称为大(或者小)顶堆。即堆顶元素为序列中的大值(或者最小值)
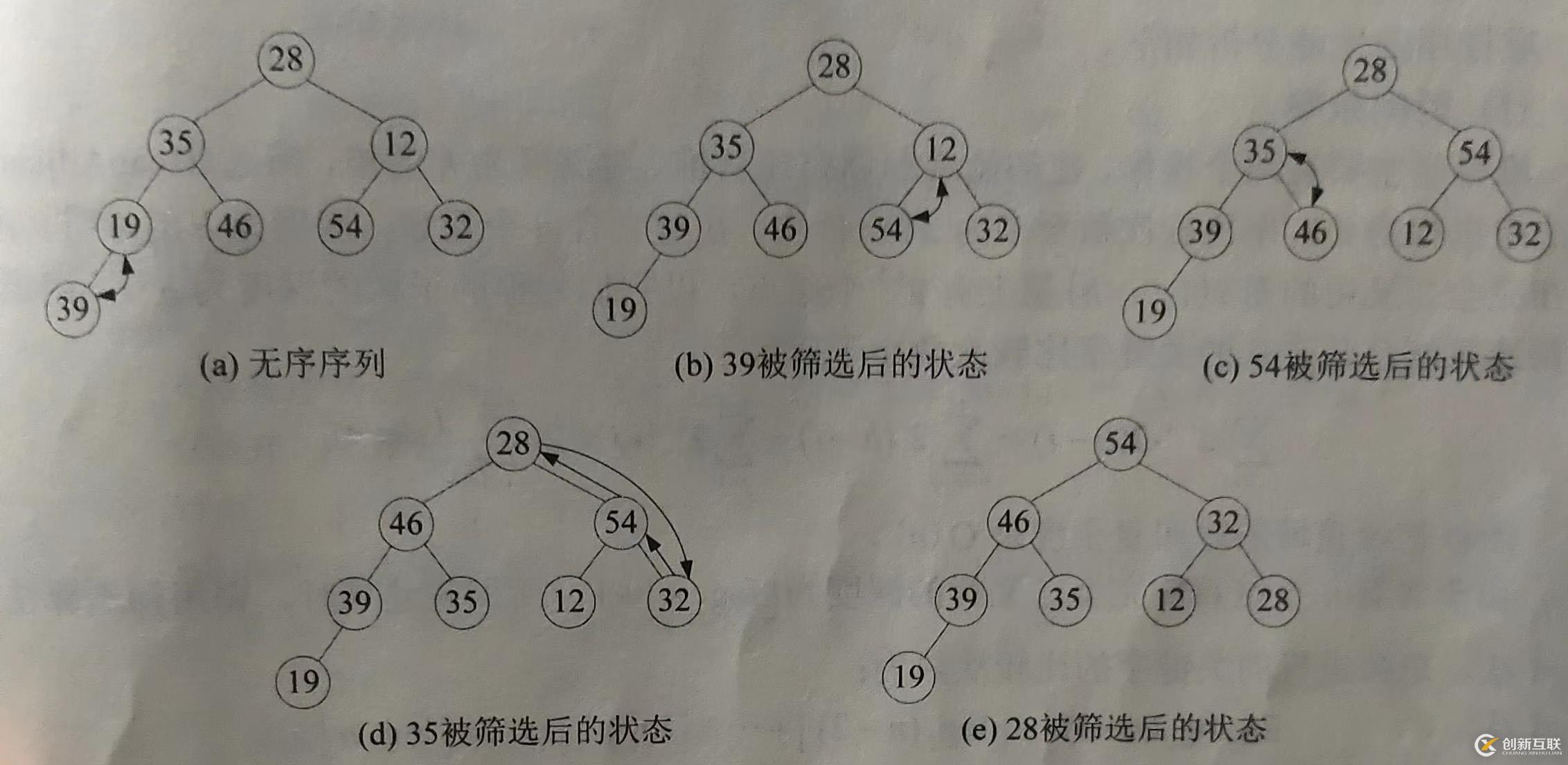
将无序序列建成- 个堆,得到关键字大(或最小)的记录,输出堆顶元素后,将剩余的n-1个元素重新建成一个堆,则可得到n个元素中关键字次大(或次小)的记录,重复执行该操作,最终得到一个有序序列,这个过程就称为堆排序。
实现堆排序需要解决如下两个问题。
①初建堆,即如何将一个无序序列建成一个堆。
②调整堆,即如何在输出堆顶元素后,调整剩余元素成为一个新堆。
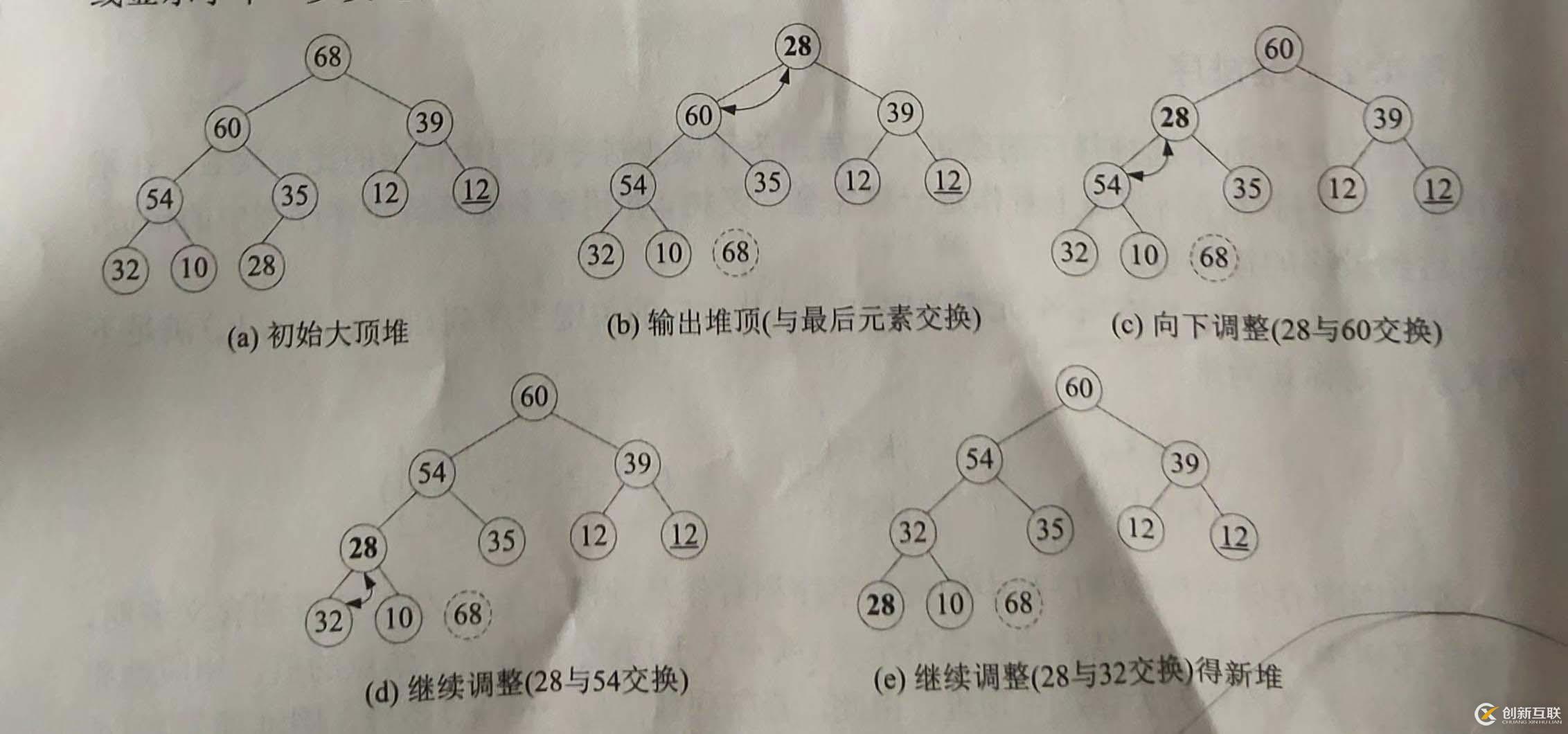
先考虑堆的调整问题。设当前所使用的堆为大顶堆,首先将堆顶元素与最后一个元素进行交换。此时,不包含最后一个元素的完全二叉树就失去了堆的性质,不再是一个堆了,但根结点的左右子树均为堆,因此可以从根结点开始,自上而下进行调整。
将堆顶元素与左右子树的根结点中关键字较大者进行比较,若堆顶元素小于子树根结点的值,则堆顶结点与子树根结点交换。因为交换可能又破坏了该子树的堆的性质,则重复上述调整过程,直至调整到该子树满足堆的性质为止。最坏情况下调整到叶子结点才结束。图8-9给出了输出堆顶元素及堆的调整过程(假设结点中的值就是关键字的值,(b)图到(d)图中用双箭头线显示了下一步要进行的交换)。
关于调整过程:
堆排序:
若想要将一个无序序列排列成一个递增的有序序列,可以在堆排序的算法中先建立一个大顶堆,将堆顶元素和最后一个元素交换,然后再调整成一个大顶堆,重复直到整个序列有序为止。
void heap(int a[], int s, int m) {
//把s到m序列调整成一个大顶堆
int k = a[s];
for(int i = 2*s; i<= m; i *= 2){
if(i=0; i--){
heap(a, i, len);
}
for(int i = len; i >1; i--){
swap(a[0], a[len-1]);//交换最后一个和首个
heap(a, 0, i-1); //重新调整
}
return;
}
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
当前名称:c语言实现数据结构---关于实现各种排序算法-创新互联
网站链接:http://scyanting.com/article/dpjipe.html

