如何进行基于DataLakeAnalytics的ServerlessSQL大数据分析
这篇文章给大家介绍如何进行基于Data Lake Analytics的Serverless SQL大数据分析,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
成都创新互联长期为上千家客户提供的网站建设服务,团队从业经验10年,关注不同地域、不同群体,并针对不同对象提供差异化的产品和服务;打造开放共赢平台,与合作伙伴共同营造健康的互联网生态环境。为石首企业提供专业的成都网站制作、成都网站建设,石首网站改版等技术服务。拥有十载丰富建站经验和众多成功案例,为您定制开发。
背景介绍
TableStore(简称OTS)是阿里云的一款分布式表格系统,为用户提供schema-free的分布式表格服务。随着越来越多用户对OLAP有强烈的需求,我们提供在表格存储上接入Data Lake Analytics(简称DLA)服务的方式,提供一种快速的OLAP解决方案。DLA是阿里云上的一款的通用SQL查询引擎,通过在OTS连通DLA服务,使用通用的SQL语言(兼容MySQL5.7绝大部分查询语法),在表格存储上做灵活的数据分析任务。
架构视图

如上图所示,整体OLAP查询架构涉及3款阿里云产品:DLA,OTS,OSS。其中DLA负责分布式SQL查询计算,在实际运行过程中,会将用户sql查询请求进行任务拆解,产生若干可并行化的子任务,提升数据计算和查询能力。OTS为数据存储层,用于接收DLA的各类子查询任务。如果用户已经有存量的数据在OTS上,可以直接在DLA上建立映射视图,实现快速体验SQL计算带来的便捷。OSS为分布式对象存储系统,主要用于用户查询结果数据的保存。
因此用户要想快速体验SQL on OTS,必须在开通OTS的前提下,完成DLA和OSS服务的开通。通过上述3个云产品的配合,用户就能在OTS上快速执行SQL计算。目前开通OSS服务的主要原因是DLA默认回查询结果集数据写回到OSS存储,因此需要引入一个额外的存储依赖,但仅依赖用户开通OSS服务,不需要用户预先创建OSS存储实例。
目前开服公测的区域是上海区,对应的实例是该region内所有的容量型实例。在开通DLA服务时,需要先填写公测申请,通过之后按照“接入方式”小节的步骤,能快速完成接入体验。
接入方式
整个主要包含OTS、OSS、DLA的服务接入。需要注意的一点是,完成接入之后,就会按照实际查询产生相应的费用。如在这个过程中,用户账号是欠费的,将会发生查询失败。
OTS服务开通
如果用户已经开通的OTS服务,并且上面已经包含存量的实例,表格数据,则忽略该步骤。
对于首次使用OTS的用户,可按照下述方式开通OTS:
登录https://www.aliyun.com;
进入“产品”->"云计算基础"->"数据库"->“表格存储 TableStore”;
按照上面的文档说明,快速建立实例和表格,进行体验;
1)使用控制台,快速创建测试表格:
2)使用控制台,快速插入测试数据:

OSS服务开通
登录https://www.aliyun.com;
进入“产品”->"云计算基础"->"存储服务"->“对象存储 OSS”;
直接点击服务开通即可。
OSS服务开通后,不需要创景对象实例,DLA接入时,会自动为用户在OSS服务中,创建用于存储查询结果数据的对象存储实例,用户不需要关心。
DLA服务开通
登录https://www.aliyun.com;
进入“产品”->"大数据"->"大数据计算"->“Data Lake Analytics”;
直接点击服务开通;
注意:处于公测阶段时,开通服务需要做公测申请,填写好相关信息即可。
DLA on OTS接入
按照下列步骤,在DLA上建立OTS的映射:
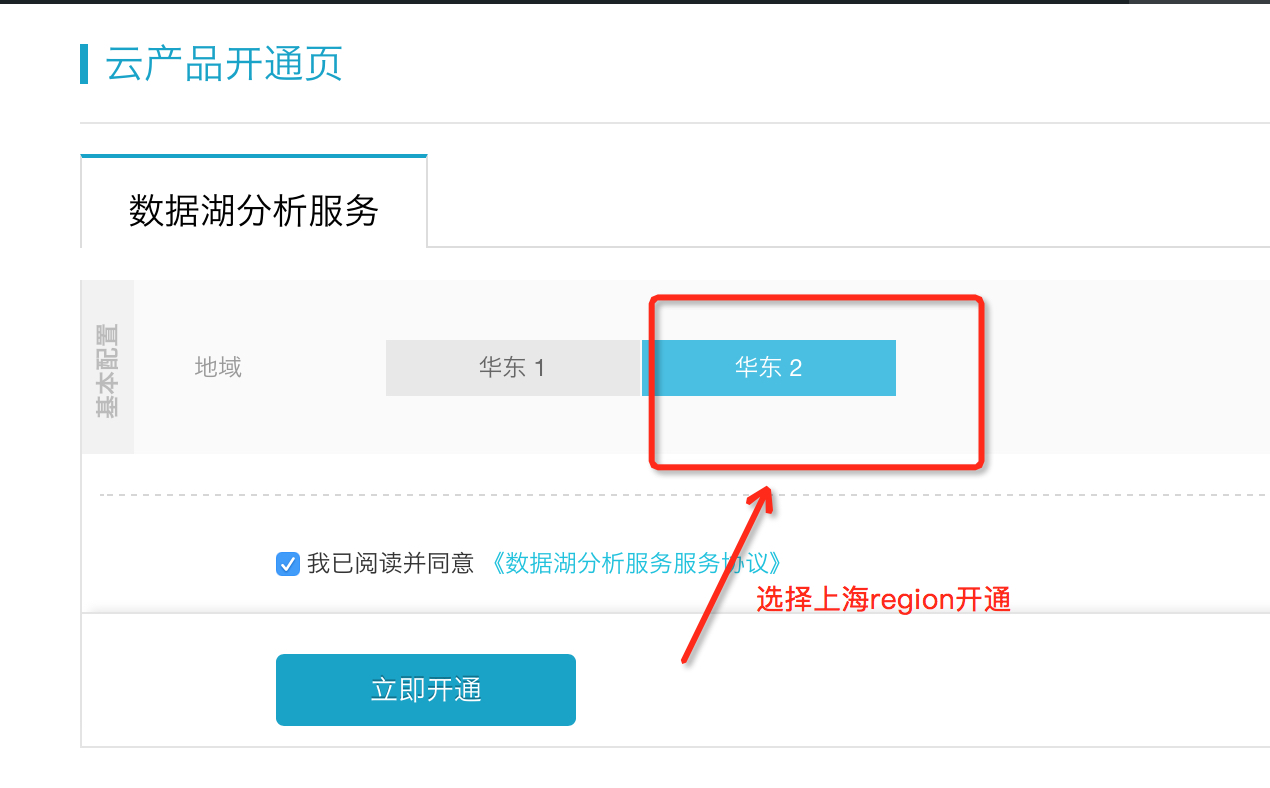
开通DLA服务之后,可以选择不同region,选择开通对应region的DLA服务实例(如现在华东2的上海区域)。不同的region,对应不同的账号,不同region的DLA账号,不能混用,
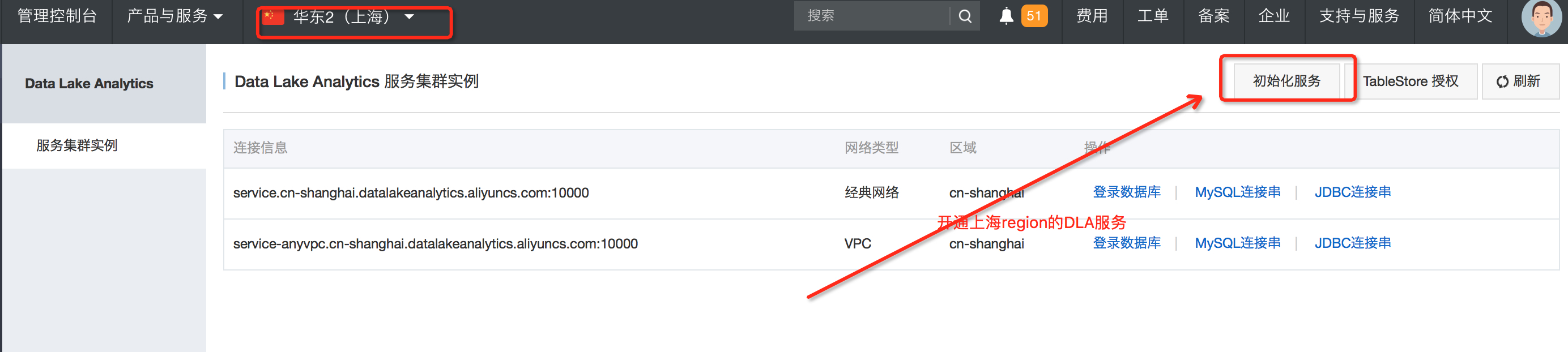  注意:账号创建完成之后,会收到相关邮件(邮箱为阿里云的注册邮箱),内含该region的DLA账号和密码,注意查收。
选择region,授权DLA访问OTS上的用户实例数据。
服务开通之后,有3中SQL访问方式:控制台、mysql client,JDBC。
控制台访问
点击数据库连接,使用邮件中的该region的用户名和密码,连接进入控制台。

进入控制台后,需要为OTS上的实例表格数据建立映射信息。场景举例:假设用户在上海region已经有一个名为sh_tpch的实例,该实例包含表格test001,里面包含2行测试数据。对该实例建立映射的步骤包括:
1)将ots的实例映射成DLA的一个DataBase实例:
在建立DLA的Database映射前,首先需要在OTS上创建一个表格存储的实例instance,如:
创建一个实例,名为sh-tpch,对应的endpoint为https://sh-tpch.cn-shanghai.ots.aliyuncs.com。
完成测试实例创建后,执行下列语句建立Database映射:
CREATE SCHEMA sh_tpch001 with DBPROPERTIES(LOCATION ='https://sh-tpch.cn-shanghai.ots.aliyuncs.com', catalog='ots', instance ='sh-tpch'); 注意:使用mysql client时,可以使用create database或create schema语句进行创建db映射;但是在控制台,目前只支持create schema语句创建db映射。
上述语句,将在DLA上创建一个名为sh_tpch001的database,对应的实例是ots的sh-tpch.cn-shanghai.ots.aliyuncs.com集群下名为sh-tpch的实例。通过上面的语句,就能产生一个ots的实例映射。
2)在tp_tpch001的DB下,建立表格的映射:
在建立DLA的表格映射前,首先需要在OTS创建测试表,流程参考"OTS服务开通"小节。
测试表格创建完成后,执行下列语句建立表格映射:
CREATE TABLE test001 (pk0 int , primary key(pk0)); 注意:主要建立DLA映射表时,指定的Primary Key必须跟OTS表格定义Primary Key列表一致。因为Primary Key必须能是唯一的定位一行,一旦映射表的Primary Key列表与OTS表格的PK不一致,则可能会导致SQL查询结果出现非预期的错误。

例如:用户的OTS实例sh_tpch上包含test001表格,其中只有一列pk0。上面的命令就完成了在DLA的实例sh_tpch001上,创建映射表test001。使用show命令能查看该表创建成功。
3)使用select语句执行sql查询:
1. 查出所有数据: select * from test001;

2. 执行count统计: select count(*) from test001;
3. 执行sum统计: select sum(pk0) from test001;

4)更为丰富执行语句,请查看如下的帮助说明文档:
create schema语句:https://help.aliyun.com/document_detail/72005.html create table语句:https://help.aliyun.com/document_detail/72006.html select语句:https://help.aliyun.com/document_detail/71044.html show语句:https://help.aliyun.com/document_detail/72011.html drop table语句:https://help.aliyun.com/document_detail/72008.html drop schema语句:https://help.aliyun.com/document_detail/72007.html
5)在做SQL执行时,可以选择同步执行结果,返回满足条件的前10000条记录;如果要获大结果集数据,需要选择异步执行,并使用show query_id的方式异步获取结果:
show query_task where id = '59a05af7_1531893489231';

mysql访问
使用标准的mysql client也能快速连通DLA的数据实例。其中连接语句为:
mysql -h service.cn-shanghai.datalakeanalytics.aliyuncs.com -P 10000 -u-p -c -A
其他操作语句跟“控制台访问”小节介绍一致。
JDBC访问
也可以使用标准的java api实现访问,连接串为:
jdbc:mysql://service.cn-shanghai.datalakeanalytics.aliyuncs.com:10000/
关于如何进行基于Data Lake Analytics的Serverless SQL大数据分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
本文标题:如何进行基于DataLakeAnalytics的ServerlessSQL大数据分析
转载注明:http://scyanting.com/article/jesege.html

